
Why And How NBA Mock Drafts Are A Sham


This post originally ran at the Harvard Sports Analysis Collective. It is reprinted here with permission.
A while back HSAC examined the (in)accuracy of projecting the NFL draft, but how hard is it for the NBA? I decided to find out by analyzing various NBA mock draft sites to see just how accurately the information they receive from team sources, agents, and hunches translates into predictive success.
I began by collecting the names and draft numbers of every NBA Draft since 2007, and then compared their real position to the position predicted by mocks. I then created a variable called accuracy, which was predicted position number minus their actual draft number. The goal, of course, was to minimize the value of accuracy. For example, in 2014 Chad Ford predicted that Nik Stauskas would be picked 12th, but the Kings picked Nik Stauskas at 8, giving Chad Ford an accuracy of +4. In 2013, Chad Ford predicted Nerlens Noel going first overall, but after sliding down to sixth, Chad Ford received an accuracy of -5. For simplicity's sake, a player who was predicted to be drafted, but wound up going undrafted, received a mock number of 61. I then split the averages into five categories: Total Draft, Lottery, First Round, Second Round, and (to give the analysts the benefit of the doubt of my arbitrary number choice for undrafted players) Total Draft not including those who went undrafted.
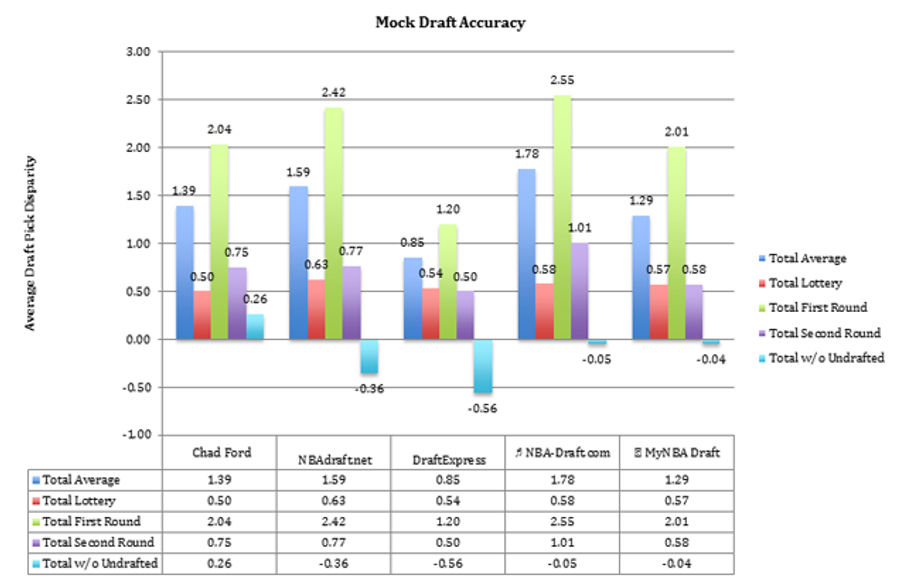
The data showed that on average, analysts were predicting players going about 1.4 spots ahead of where they ended up being picked. This was incredibly low. Sure, one and a half picks is the difference between John Wall and Evan Turner, but every analyst getting that close for a whole draft seemed preposterous. The real story lied in the difference between the total average and the total without undrafted players average. A healthy mix of picks that were way too far ahead and way too far behind would give analysts an artificially reduced low overall accuracy number. Hypothetically a mock draft could get zero picks right and simply have their draft going in reverse order with Andrew Wiggins being picked last and Cory Jefferson being picked first, and this would result in the same total accuracy as a mock draft that correctly predicted every pick. Thus, I decided to present the data in terms of absolute distance from the correct pick number, rather than average total distance.
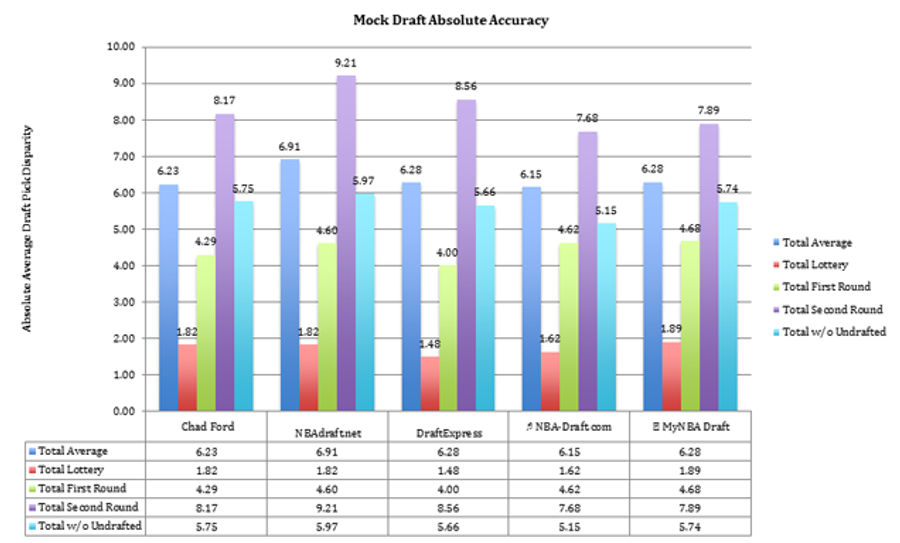
Six picks! Forget John Wall and Evan Turner, six picks is the difference between Rajon Rondo and Sergio Rodriguez. Equally surprising was that there is no evidence to support that Chad Ford is any better at creating mock drafts than anyone else. This second chart is especially damning, because it suggests a very basic (and inaccurate) formula has found prevalence in major mock drafts.
Overall, the seeming randomness of the mock draft accuracy troubled me. There was just too much data for everyone to be so alike. So, I decided to check the year-by-year mock draft accuracy to see if perhaps it was maybe just one particularly difficult draft that had been dragging the accuracy down. At the very least, I hypothesized, there should be a downward trend in my accuracy variable, as experts continued learning from their mistakes, gaining experience, and connecting to new inside sources that could provide them more reliable information.
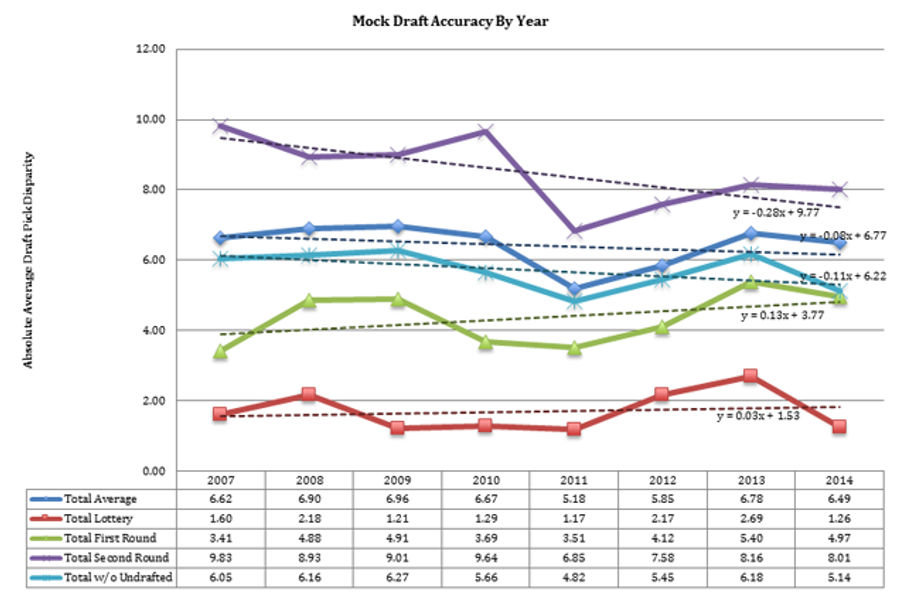
Instead, however, I found quite the opposite. The only significant trend year-to-year appeared to be the growing accuracy of second round picks, by about .3 picks per year. This makes sense, with the added focus on the value of draft picks in recent years. Besides that, the rest of the trends not only didn't improve, but continued to display almost total randomness.
How random were they? I decided to create my own mock draft to find out, with one wrinkle: My expert sources would be a random number generator, choosing draft picks at random under different sets of circumstances. First, I ran 50 random mock drafts where each player was randomly assigned a number and averaged them. Then, I repeated the process after dividing the players into first and second rounders and assigned them a number. Then, first, second and lottery. Then, top 5, lottery, first, and second. Finally top five, lottery, first, first half of second, and second half of second. The results were pretty astounding.
| No Specifications | Divided Into Rounds | Divided Into Rounds & Lottery | Divided Into Rounds, Lottery & Top 5 | Divided 1-5, 6-14, 15-30, 31-45, 46-60 | |
| TOTAL AVERAGE | 20.19 | 9.77 | 7.64 | 6.92 | 4.51 |
| TOTAL LOTTERY | 24.8 | 10 | 4.63 | 2.43 | 2.35 |
| TOTAL FIRST ROUND | 20.43 | 9.78 | 4.89 | 4 | 4.02 |
| TOTAL SECOND ROUND | 19.95 | 9.75 | 10.39 | 9.83 | 5 |
| TOTAL W/O UNDRAFTED | 20.19 | 9.77 | 7.64 | 6.92 | 4.51 |
In just three easy steps of specification, I could pretty much emulate the success of any mock draft using random numbers. Using five total classifications, I could blow them out of the water in every category. As it turns out, this is essentially the same formula most mock drafters follow.
Mock drafters create broad classifications, such as "Consensus Top 5", "Fringe Lottery", or "Second Rounder", and from there, the data suggests that they pretty much guess. Does this mean that mock drafters are stupid and a random number generator should just replace their mock drafts? Absolutely not. It still takes skill to determine under what category a prospect falls, and even more to figure out if NBA GMs are going to agree with your categorization. Rather than using NBA Mock Drafts as a pick-by-pick benchmark for how good a pick is, maybe we should accept mock drafts for what they are: A wide guess of a player's range—at best. When it comes to the NBA Draft, there are no expert opinions, no confirmed inside sources, and nothing is consensus. After all, what is Chad Ford but a random number generator?
Fri Lavey is a sophomore at Harvard studying applied math economics and computer science. Last summer he worked as a front-office intern for the Philadelphia 76ers. He hopes to continue writing and working in sports analytics.
Photo credit: Mike Stobe / Getty Images Sport










- Best NBA Betting Picks and Predictions for Monday April 6th
- National Championship Bet Pick: Why Michigan Has the Edge Over UConn
- UFC Vegas 115 Betting Picks: Moicano vs. Duncan Headlines April 4th Card
- NBA Betting Picks April 4th: Three Best Bets for Saturday's Slate
- Michigan vs. Arizona Bets: Wolverines Hold Edge in Final Four Showdown
- Best NBA Betting Picks Today: Friday April 3rd Expert Predictions
- MLB Pitcher Props Today: Best Baseball Bets for April 3rd
